
In April 2017 Cognex made a significant move with their acquisition of ViDi Systems SA, which brings Deep Learning capability into Cognex’s offering. This article reviews the ViDi Deep Learning tool and its potential impact on industrial computer vision.
Background
Cognex’s image processing tools have traditionally been ‘rules-based’, using classic computer vision techniques such as pattern matching and keypoint detection. As described in a previous Agmanic Vision blog article on Machine Learning, rules-based techniques struggle when faced with tasks requiring human-like interpretation and judgement. The advances in GPUs (Graphics Processing Units) and the parallelization of neural networks made in 2012-2014 gave rise to Deep Learning, a more powerful version of Machine Learning suited to processing images, video and speech. ViDi Systems SA was launched in Switzerland in 2012, originally with the objective of applying Deep Learning concepts to find defects in textiles. Cognex, recognizing the potential of Deep Learning in industrial applications, made a decisive move to integrate ViDi into their offering.
Deep Learning made easy
The success of Cognex’s VisionPro tool, their flagship rules-based image processing library, is down to its ease of use – application developers can build and configure defect detection workflows without being an expert in computer vision or programming. Cognex ViDi takes the same approach – users label input images and configure training workflows with a graphical tool rather than writing code, as is required with open source Deep Learning tools such as TensorFlow. Additionally, only a basic understanding of Deep Learning concepts is required to operate ViDi – the application developer is not required to understand neural network architecture or transfer learning.
ViDi is structured into 4 distinct tools – Analyze, Locate, Classify and Read – which are explained in the following sections.
ViDi Analyze
The purpose of the Analyze tool is to detect anomalies and aesthetic defects. There are two modes – Unsupervised and Supervised. In Unsupervised mode we teach the tool the appearance of good parts, which it then uses as a basis for detecting anomalies i.e. deviations from the learned good parts. This requires that anomalies are visually sufficiently salient to be separable from the rest of the image. Once good parts have been learned by the Unsupervised tool, anomalies can be detected in new images – see below.
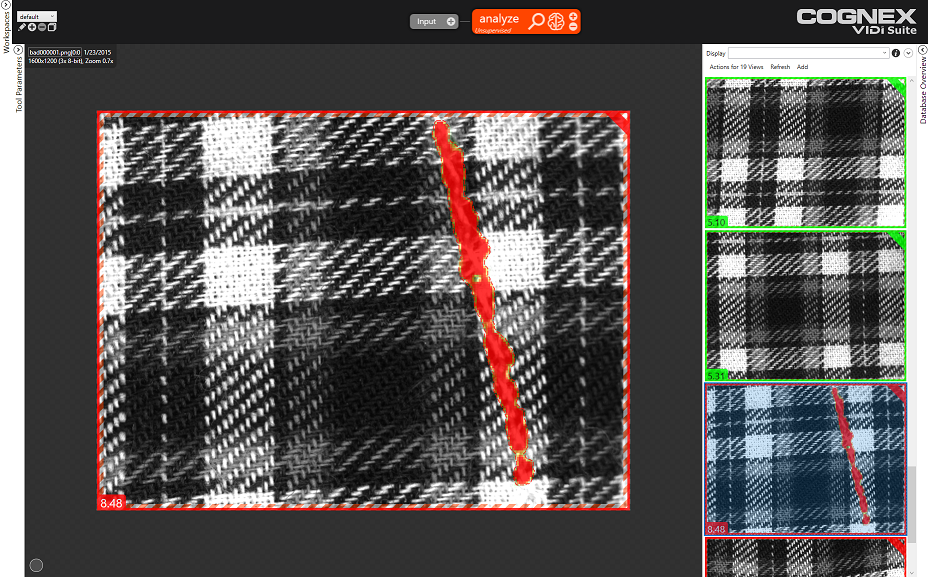
In Supervised mode we teach the tool the appearance of defects, manually identifying the exact location and shape of the defects in the training images. The ViDi graphical interface provides a number of easy to use tools for labeling defects with the click of a mouse. Supervised mode is applicable when the defects are not sufficiently different from the image background to be detected in Unsupervised mode.
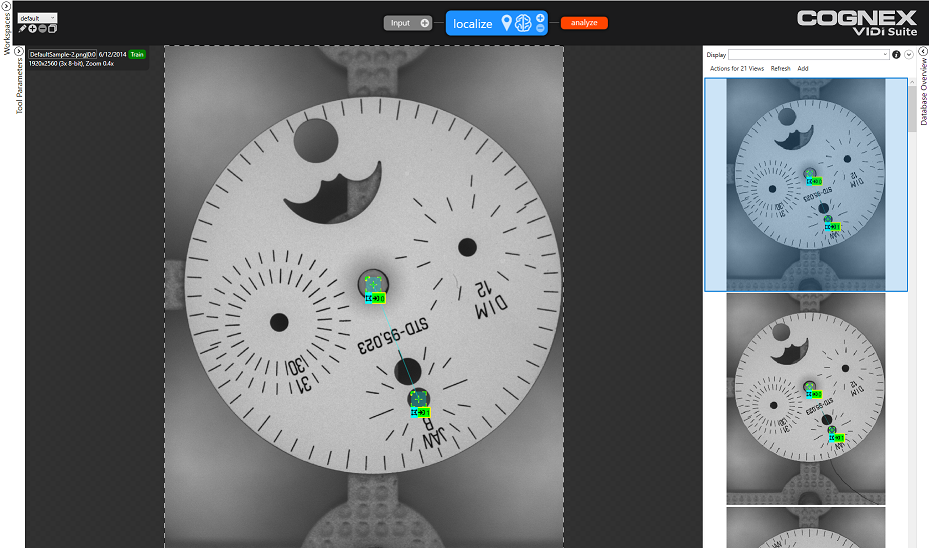
ViDi Locate
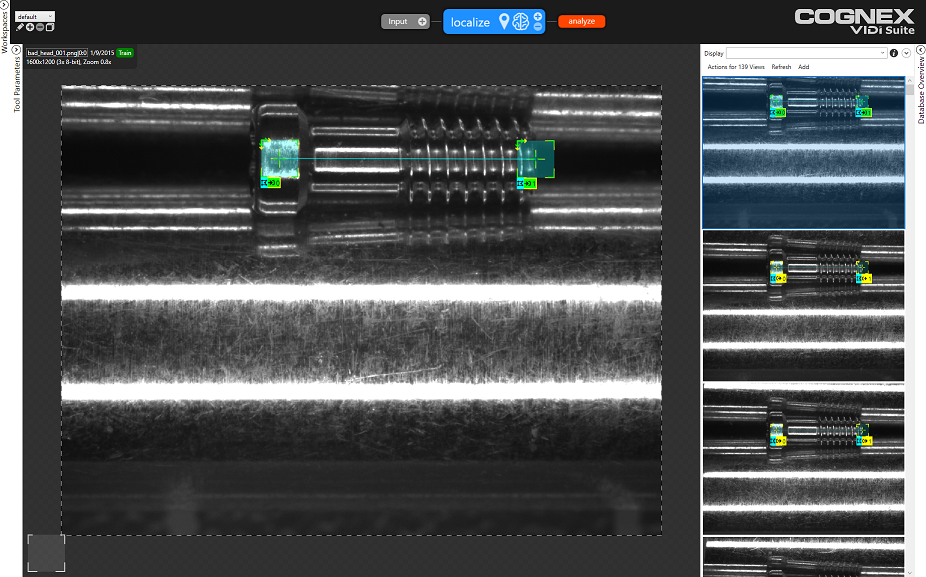
The Locate tool learns patterns in the training images which are then used to locate features in new images. This is typically used for locating a part in a broader scene and segmenting the region of interest for further analysis. The example below shows features located at the two ends of a screw, which subsequently segment the screw from the rest of the image and feed it into the ViDi Analyze tool.
ViDi Classify
The ViDi Classify tool is straightforward image classification. The training images are assigned a single class which the underlying neural network learns. Note that ViDi Classify does not perform object detection and location within the image – the class is assigned to the image as a whole, not to a specific location within the image.
ViDi Read
The final tool to discuss is ViDi Read, which performs Deep Learning based OCR (Optical Character Recognition). ViDi Read’s objective is the same as Cognex VisionPro’s OCRMax tool but the approach is different. Rather than taking a rules-based approach as done by OCRMax, ViDi Read learns character patterns from a training set of images which it applies to identify new characters. ViDi Read is appropriate when attempting to read distorted, damaged or poorly printed characters.
Considerations
Cognex ViDi has two clear selling points. Firstly, it’s able to address inspection tasks which are not possible with rules-based techniques. Secondly, it provides an easy to use application development interface which doesn’t require knowledge of Deep Learning or programming. There are however a number of disadvantages to consider. Cost is a key driver in vision projects; ViDi comes with a hefty price tag for development and run-time licenses. A company purchasing a ViDi license would need to apply it over a sufficient number of projects to amortize its cost. Secondly, Deep Learning neural networks typically require graphics processors (GPUs) to perform training in a reasonable time delay. ViDi can only be trained locally – it cannot be cloud trained e.g. using Amazon Web Services GPUs – therefore application developers must invest in GPU-equipped development hardware. The final consideration is ViDi’s ‘black-box’ nature. Whilst being an advantage in terms of ease of use, ViDi’s graphical interface abstracts the application developer away from the neural network design, limiting the degree to which the tool can be customized to solve trickier use cases.
Conclusion
Overall, Cognex have made a significant and impressive move, enhancing their offering by integrating the latest Deep Learning technology in the form of ViDi. This provides the ability to address far more complex inspection tasks than those possible with Cognex VisionPro, without the need for Deep Learning expertise. What remains to be seen is how ViDi will fare against open source Deep Learning tools such as TensorFlow.