When applied correctly, Machine Learning allows organizations to address previously unsolvable problems. From predictive maintenance to inventory management, Machine Learning is turbo-charging decision making. This article cuts through the hype by providing a concrete and concise introduction to what Machine Learning is and the scenarios in which it is best applied.
Machine Learning vs Classical Programming
All businesses have a set of rules which determine how they operate, also known as ‘business logic’. For example, an insurance firm has rules to determine how an insurance policy is priced as a function of client profile and risk. A manufacturing operation has rules to determine machine settings as a function of the materials used. A hospital has rules to determine how patients are triaged. Prior to the introduction of Machine Learning, all business rules were determined manually through experience and analysis, known as Classical Programming. The underlying principle of Machine Learning is to automate the derivation of business rules using data and algorithms.
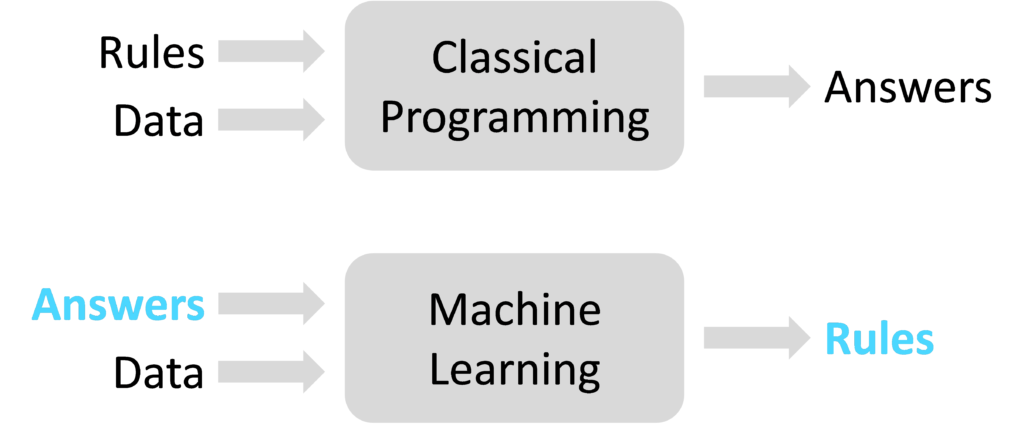
Consider an email spam classifier, reviewing incoming email and filtering out spam. The classifier could be created using Classical Programming, manually writing out spam detection rules based on words used in the email body and information in the email metadata. For complex problems such as spam detection, the manual Classical Programming approach quickly breaks down as the list of rules becomes long, with many combinations to manage. When solving this problem with Machine Learning, a dataset of email examples is fed into a learning algorithm which automatically derives the spam detection rules.
As another example, consider the recent use of Machine Learning to beat world champion Go player Lee Sedol in 2016. The computer AlphaGo was fed a large number of Go scenario examples, from which it learnt its own rules for playing Go. This approach is significantly different to that used by the Deep Blue computer which beat world champion chess player Garry Kasparov in 1996. Deep Blue was designed using Classical Programming; its approach to playing chess was manually and explicitly defined by humans.
Classical Programming: Deep Blue vs Gary Kasparov, 1996

Machine Learning: AlphaGo vs Lee Sedol, 2016

Categories of Machine Learning
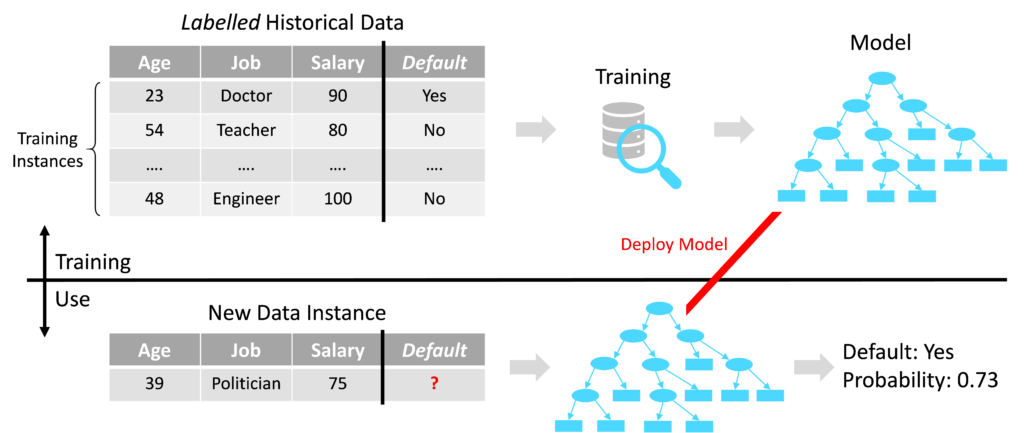
There are two overall categories of Machine Learning: Supervised and Unsupervised. Consider a bank wanting to predict if a potential new mortgage customer will default on payments. The bank needs a set of business rules which they can apply to assess potential new customers. Historical data is gathered on previous customers, for which it is known whether a payment default occurred. This data is fed into a Machine Learning algorithm to automatically generate the business rules for assessing new customers. The term ‘supervised’ refers to the fact that the answer to the question is known for the historical data i.e. if a payment default occurred. This variable is known as the ‘target’. In addition to the target variable, the dataset contains ‘features’ which describe the previous customers in a manner relevant to the problem being solved e.g. age, job type, salary etc. A Machine Learning algorithm identifies the patterns linking the features with the target and represents these patterns as a model. The model can then be deployed as a set of business rules to assess potential new mortgage customers. Each previous customer is known as a ‘training instance’. Data for which the target is known is referred to as ‘labelled’ data.
Unsupervised Machine Learning refers to unlabelled datasets i.e. data for which the target is unknown. Consider a set of unlabelled images, with no indication of what each image represents. An unsupervised Machine Learning algorithm finds patterns and structure in the unlabelled dataset.

Business Applications of Machine Learning
Considering the underlying principle of Machine Learning described earlier in this article, to automate the derivation of business rules using data and algorithms, there are three overall business applications:
- Creating business rules for problems involving a significant number of variables and combinations
- Creating business rules for problems which change over time and require adaptivity
- Gaining insights into large amounts of high-dimensional data and allowing it to be visualized
It is important to recognize that many business problems can still be solved using Classical Programming i.e. manual derivation of business rules performed by a business analyst. Adoption of Machine Learning is appropriate and beneficial only when at least one of the three situations described above applies.
Categories of Problems which can be solved with Machine Learning
Beyond the three high-level business applications described above, there are four key use-cases which represent the vast majority of practical Machine Learning usage:
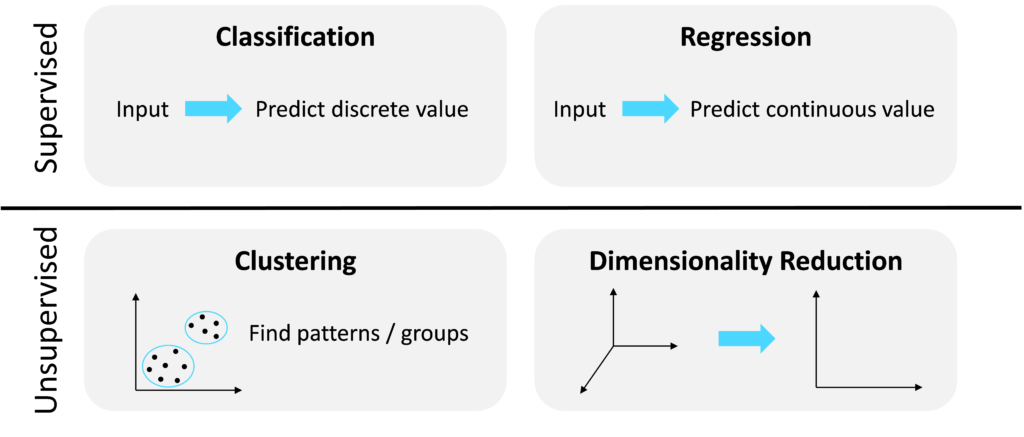
- Classification is a supervised technique used to predict discrete values. Examples include classifying email as spam or ham and classifying a tumor as cancerous or benign.
- Regression is also a supervised Machine Learning technique however the output is a continuous rather than discrete value. Examples include predicting the price at which a house will sell, predicting the future price of stock and setting factory machine speeds.
- Clustering is an unsupervised technique which finds patterns and structure in unlabelled data. Examples include discovering segments in a customer base, finding patterns in customer enquiries and analysing social media posts.
- Dimensionality Reduction is the second main unsupervised Machine Learning technique, aimed at collapsing high-dimensional datasets down to a smaller number of dimensions for analysis.