
In a previous article on object detection, we described how keypoint matching can be used to locate objects in a cluttered scene. In this article we’ll explore how keypoint matching can be used to perform image classification with a technique called ‘Bag of Visual Words’.
Challenges with keypoint matching
If we have a single, known pattern which we want to detect, such as a logo, keypoint matching can reliably find the pattern in a scene. The demonstration below takes a single search image (top left) and finds matching keypoints in the scene.

The first challenge of matching keypoints to a single pattern is that the object we are trying to detect may have several possible variations. For example, fire exit signs come in many different formats therefore a single search image would not be sufficient for a fire exit sign detector.

Secondly, we may wish to distinguish between different types of objects, associating them with a class. For example, a road sign detector for a self-driving car would need to not only detect the presence of a road sign but also determine the type of road sign so that appropriate action can be taken by the vehicle’s control system.

The ‘brute force’ answer to the two challenges identified above is to gather a set of search images which represent both the different classes and the variations within each class then exhaustively search for all of the images in a given scene. The issue with this brute force approach is that it becomes very computationally intensive. Matching keypoints between just a single search image and a given scene can take as long as several seconds, depending on the image size and the number of keypoints found. Attempting to match tens or even hundreds of search images could therefore take an unacceptably long period of time.
The solution – Bag of Visual Words
As an alternative to the brute force approach described above, which can be very heavy on processing, the BOVW (Bag of Visual Words) presents a more elegant means of distinguishing between classes and accounting for in-class variation whilst levering keypoint matching. The BOVW concept is taken from the Bag of Words technique used in text processing. When performing text based search, the Bag of Words model represents a document as a set of keywords appearing in the document whilst disregarding the order in which the keywords appear. Other documents which share a significant number of the same keywords are considered relevant matches, again disregarding the order of the words. Comparing documents as a Bag of Words is highly efficient as we don’t have to store any information regarding the order or locality of the words relative to one other. In Computer Vision, our visual words are patches of an image and their associated feature vectors. The term ‘bag’ refers to the concept that strategically selected patches of the image are thrown into a bag in which order and locality is disregarded.

When performing classification with the BOVW model, we must build a ‘vocabulary’ of words to provide a means of distinguishing between different images and assigning class labels to them. The following steps describe how this is performed.
Step 1: Extract Keypoint Features
Once we have a set of training images which represent the classes we want to identify and account for variations within each class, the first step is to extract visual words from each of the training images. Visual words are extracted from each training image using keypoint detection and extraction algorithms such as SURF and RootSIFT. Keypoint detectors use corners, edges and blobs to find low level features in images. Keypoint extractors then represent a small patch surrounding each keypoint as a vector. For example, 944 keypoints were detected in the stop sign below using a SURF keypoint detector. Each of these 944 keypoints is then represented as a 128 value vector using a RootSIFT keypoint extractor. This collection of 944 RootSIFT vectors is the Bag of Visual Words for our image. The 944 RootSIFT vectors of 128 values go into a ‘bag’ in which we disregard their relative order and locality.

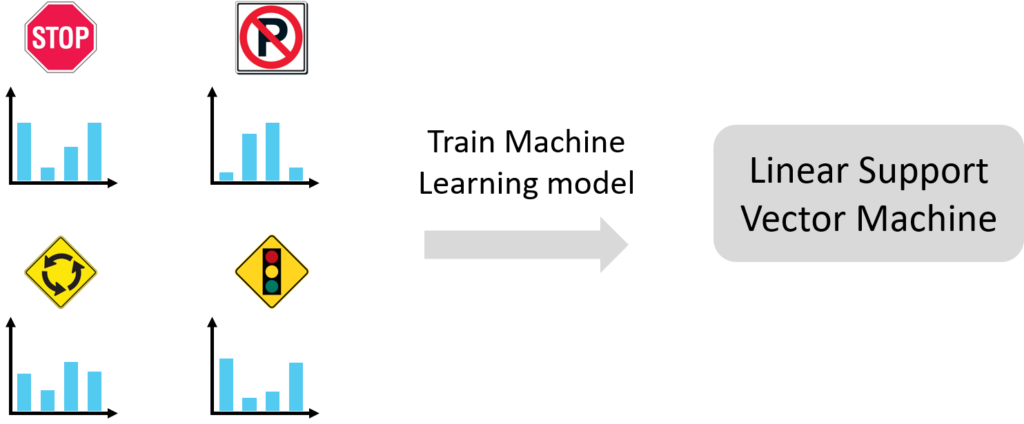
Keypoints and feature vectors are extracted in the same fashion for all of our training images and assembled into one large BOVW. The image below shows four road sign classes – in practice we would have tens or hundreds of each road sign class to represent the in-class variations.

Step 2: Create the BOVW Vocabulary
Having extracted keypoint feature vectors (visual words) from each of our training images, the next step is to create a BOVW vocabulary. The purpose of the BOVW vocabulary is to provide a means of comparing images and distinguishing between them. Concretely, the BOVW vocabulary is a limited set of the most common visual words found in the training set. A k-means Machine Learning algorithm is typically used to find a pre-defined number of clusters in the complete training set BOVW, resulting in a concise BOVW vocabulary. Once this BOVW vocabulary is established, it forms the x-axis of a histogram which can then be used to compare and classify images.

Step 3: Create BOVW Histograms
Having determined the ‘bins’ of our histogram using the BOVW vocabulary, we return to our training images and create a histogram for each of our training images. For a given training image, each extracted visual word is mapped to its closest visual word in the BOVW vocabulary. The frequency count of the closest visual word in the BOVW vocabulary is then incremented. This results in a histogram for each training image, representing each training image as a frequency count against the BOVW vocabulary.

Step 4: Train a Linear SVM (Support Vector Machine)
Having generated a BOVW histogram for each of our training images, the final step in setting up our image classifier is to train a SVM (Support Vector Machine) on the BOVW histograms. Once trained, the intention is that the SVM is then able to take the BOVW histogram for a new image which was not part of the training set and correctly classify it.
Classifying New Images
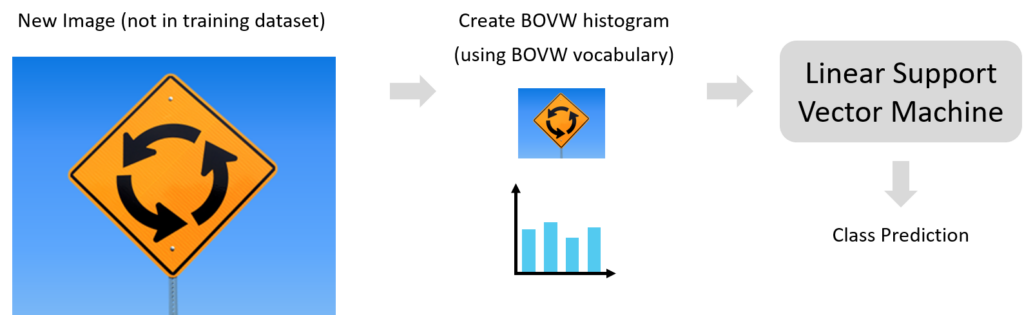
Having fully completed the BOVW classifier training pipeline, we can take a new image, extract keypoints (visual words), generate a histogram of the image’s keypoints using the BOVW vocabulary then present the histogram to the Support Vector Machine for classification.
Conclusion
The BOVW (Bag of Visual Words) offers a powerful classification technique which can achieve impressive results with a relatively small number of training images. As can be seen from the steps outlined above however, there are many parameters to be tuned in the training pipeline therefore methodical optimization is required.